In general, how to measure statistical evidence precisely in Bayesian analysis is a challenging
problem. This project discusses how to make inference for the exponential distribution model in the context
of Bayesian analysis, using a particular measure of evidence – the relative belief ratio, to illustrate how
it can be used to make statistical reasoning precisely.
Throughout the project, the evidential approach to the proposed statistical problem is emphasized,
and analyses include the following sections
Within the Bayesian inference context, one popular method to measure statistical evidence is to use the
Bayes factors, where large values of Bayes factors correspond to strong evidence for hypothesis assessments.
However, it has been shown that in some examples such as the Jeffreys-Lindley’s paradox, the Bayes factors
can be problematic and cannot fit into the general theory of statistical reasoning (strictly speaking).
As opposed to measures such as Bayes factors, for the relative belief principle, measure of evidence is separated from the measure of its strength, and therefore can solve many of the paradoxes. In other words, the relative belief ratio seeks to measure evidence by the amount of belief change from priori to posteriori, and uses probability to only measure the strength of evidence but not the evidence itself.
The first step is to select a prior for the rate parameter (lambda) of the exponential distribution model. For this problem, the prior distribution π(.) is selected to be the gamma distribution for the following reasons:
The second step involves how to quantify both the bias against and bias in favor for hypothesis assessments in this problem. This gives a way to see if the selected prior is inducing significant bias into the inference, and therefore to decide whether another prior should be used.
The third step is to estimate the model based on the data. The following procedures are involved in this step:
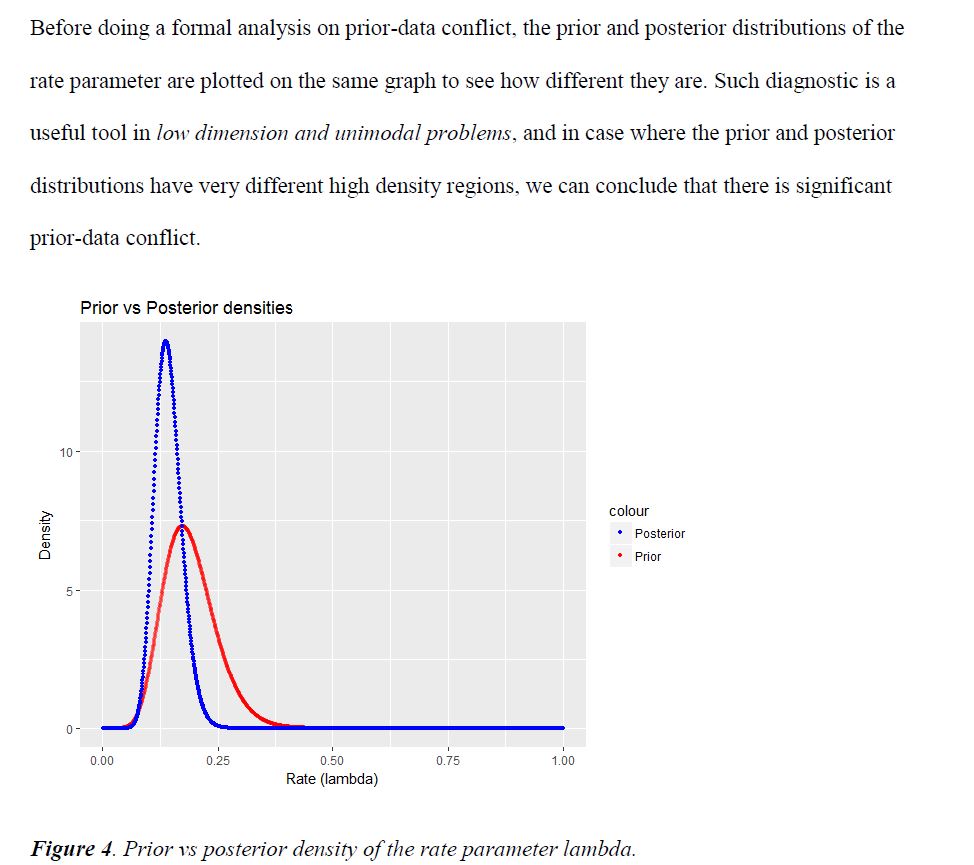
After making sure the sampling model is a reasonable choice for the observed data, now it is important to make sure the selected prior does not have significant conflict against the observed data. Prior-data conflict essentially means that the selected prior is placing most of its mass on parameter values which is surprising given the observed data.
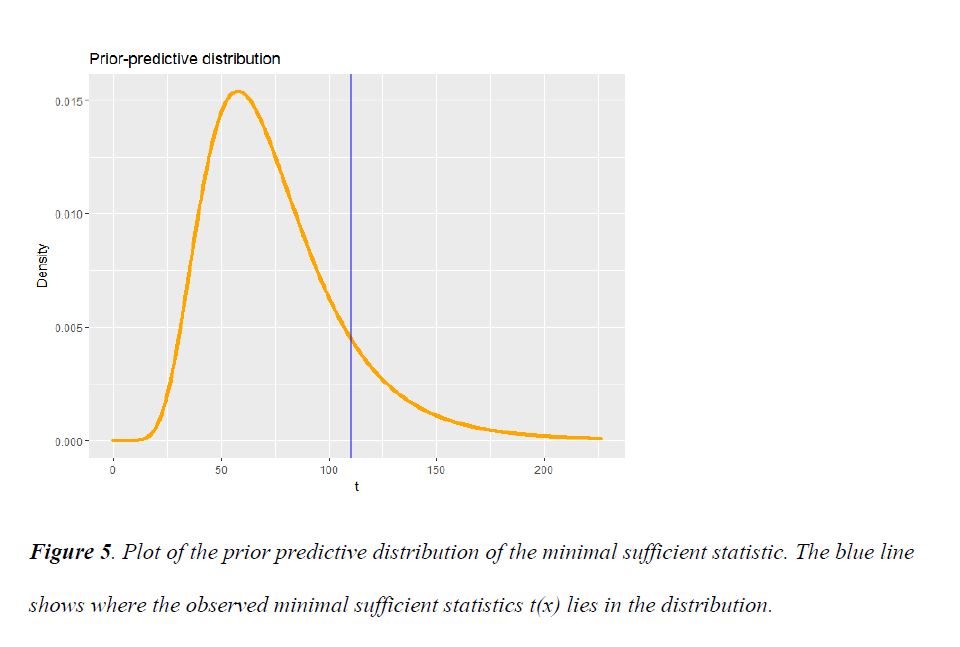
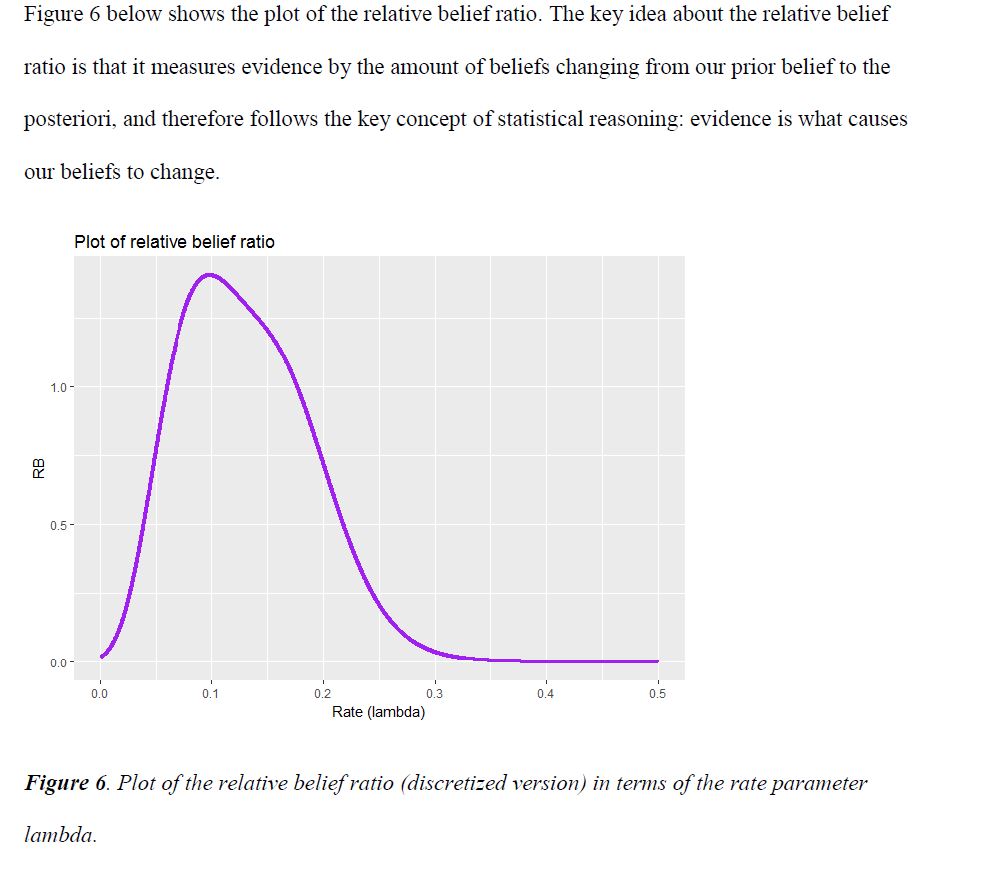
Last updated on Nov 1, 2019